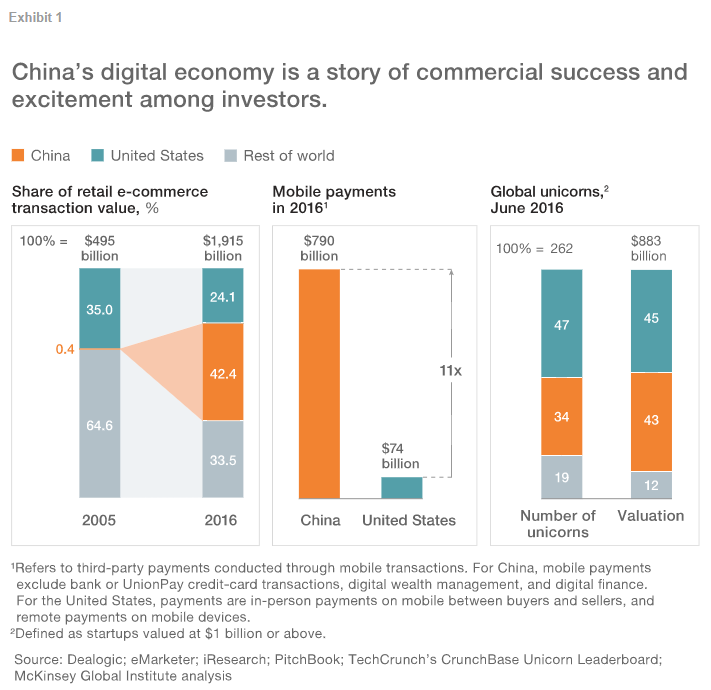
When thinking about global economic shifts, most people look to the West—Wall Street, Silicon Valley, Frankfurt, London. But over the past two decades, the quiet (and sometimes not-so-quiet) story has been happening in the East.
Asia’s middle class isn’t just growing. It’s exploding.
And yes—it’s going to shift the balance of the global economy in ways that are already underway.
What’s Actually Happening?
The Asian middle class is rising at a pace the world hasn’t really seen before. According to data from the OECD and World Bank, countries like China, India, Indonesia, the Philippines, and Vietnam have seen massive reductions in poverty and a corresponding increase in middle-income households.
Some stats worth noting:
- By 2030, Asia is expected to represent two-thirds of the global middle class population.
- China already has more middle-class consumers than the entire population of the United States.
- India is projected to add over 140 million middle-income households in the next decade.
This isn’t just a demographic shift. It’s a consumer revolution.
The Power of Consumption
A rising middle class brings with it predictable behavioral shifts:
- More spending on healthcare, education, and personal tech
- Increased demand for cars, travel, and homeownership
- Growth in e-commerce, fintech, and lifestyle brands
Global companies are already restructuring operations to cater to these new consumers. The next Apple store or Tesla factory isn’t necessarily aimed at San Francisco or Munich—it’s aimed at Chengdu, Bangalore, or Jakarta.
Will This Affect the Global Economy?
Short answer: yes. Long answer: it’s already happening.
Here’s how:
1. Shifting Demand Centers
Global demand is moving East. Multinationals that previously focused on Western markets are now pivoting their R&D, marketing, and distribution towards Asia. That means more global economic decisions being influenced by Asian markets, not Western ones.
2. Stronger Currencies and Capital Flows
More middle-class wealth = more savings, more investments, and a bigger role in global financial markets. Asian stock markets, mutual funds, and real estate are becoming increasingly influential.
3. New Innovation Hubs
With more capital and talent staying in-region, innovation ecosystems in places like Singapore, Shenzhen, and Bengaluru are competing with Silicon Valley—not just as outsourcing destinations but as product creators.
4. Cultural Rebalancing
As disposable incomes rise, so does the demand for culturally-relevant entertainment, media, and education. K-pop, anime, Bollywood, and C-drama aren’t niche anymore—they’re global exports.
A Double-Edged Sword?
This shift is exciting, but it comes with pressure:
- Environmental stress – more consumption = more emissions unless there’s a clean pivot
- Inequality – not everyone is rising equally; rural-urban divides and class gaps are still stark
- Geopolitical friction – economic power shifts often lead to realignments and, sometimes, tension
Final Thoughts
Yes, the middle class in Asia is growing faster than almost anywhere else. And yes, it’s reshaping the global economy.
But this isn’t just about GDP charts or population numbers. It’s about a change in who shapes the future—from consumers to creators, from followers to trendsetters.
For anyone building for the global market, the message is clear: look East, or risk being left behind.